ワンステップ
QQのスクリーンショット 20220402201217.jpg (142.77 KB, ダウンロード: 48)
添付ファイルのダウンロード
2022-4-2 20:12 アップロード
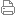
あなたのサイト https://down.itsvse.com 、URLにGETパラメータを持ついくつかのページが、他のページ(GETパラメータなし)のコンテンツと重複しています。 例えば、 https://example.com/tovary?from=mainpage は、 https://example.com/tovary と重複して います。 両方のページがクロールされるため、次のような時間がかかる可能性があります 。 両方のページがクロールされるため、重要なページの情報が検索データベースに追加されるまでに時間がかかる可能性があります。 これはサイトの検索ステータスに影響を与える可能性があります。 以下は、重要でないGETパラメータを持つページとその重複ページの例です。 ReturnUrlhttps://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/Index?ReturnUrl=%2FUser%2FCollectReturnUrl:https://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/2Fユーザー%2FリソースReturnUrl: ... %2FUser%2FResourceshttps://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ ... oadLoading%2FkzkalrReturnUrl: ...https://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ ... フィテム%2Fawljnq.htmlReturnUrl: ...https://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ ... ロードローディング%2F11820これらのページが重複している場合、robots.txtのClean-paramディレクティブを使用することをお勧めします。同一ページからのシグナルをメインページに統合します。
あなたのサイトのhttps://down.itsvse.com上的URLにGETパラメータを持ついくつかのページは、他のページ(GETパラメータなし)のコンテンツをコピーします。例えば、 https://example.com/tovary?from=mainpage とhttps://example.com/tovary重复。これらのページは両方ともクロールされているため、重要なページの情報を検索データベースに追加するのに時間がかかる場合があります。これはサイトの検索ステータスに影響を与える可能性があります。 以下は、重要でないGETパラメータを持つページと重複ページの例です: ReturnUrl:https ://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/Index?ReturnUrl=%2FUser%2FCollectReturnUrl: https ://down.itsvse.com/Account/Indexhttps ://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ ... 2Fユーザー%2FリソースReturnUrl:https ://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ ... oadLoading%2FkzkalrReturnUrl:https://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ ... フィテム%2Fawljnq.htmlReturnUrl:https ://down.itsvse.com/Account/Indexhttps://down.itsvse.com/Account/ロードローディング%2F11820これらのページが重複している場合、ボットが無関係なGETパラメータを無視し、同じページからのシグナルをホームページにマージするように、robots.txtでClean-paramディレクティブを使用することをお勧めします。
レポート
報告する
このバージョンのインテグラルルール投稿 返信返信と中継返信と最後のページへジャンプ
|( 鲁ICP备14021824 号-2)|サイトマップ
GMT+8, 2024-9-19 04:29





 发表于2022-4-2 20:12:51
发表于2022-4-2 20:12:51


 ブ
ブ ックマーク
ックマーク 发表于2022-4-4 11:36:58
发表于2022-4-4 11:36:58 楼主| 发表于2023-3-15 20:07:00
楼主| 发表于2023-3-15 20:07:00